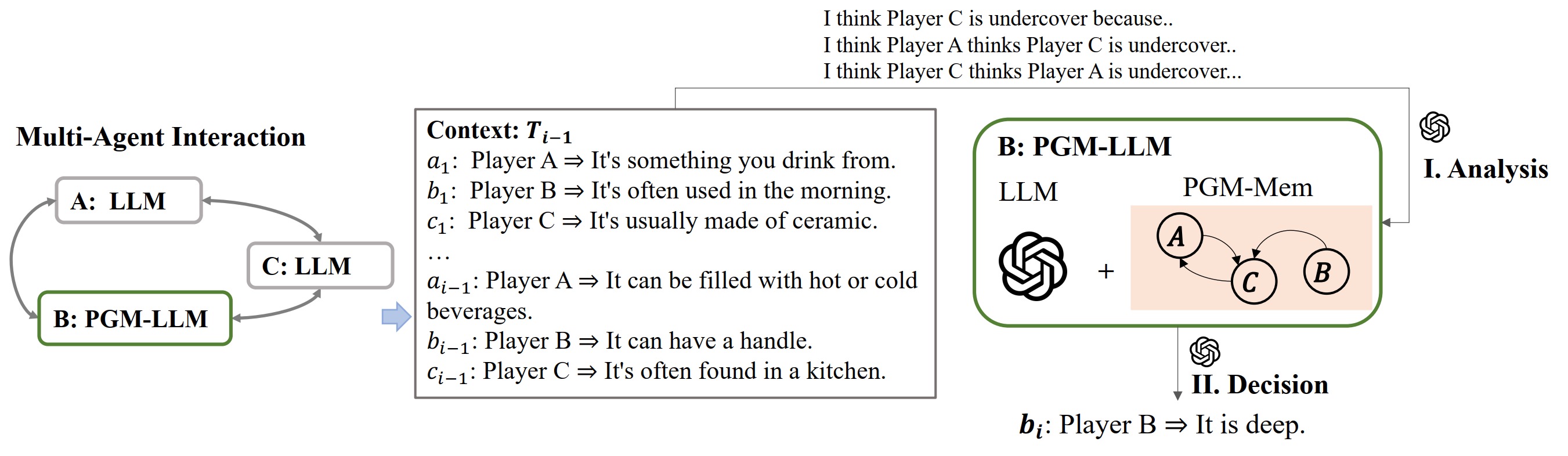
How about current LLMs-powered Multi-agent's capabilities
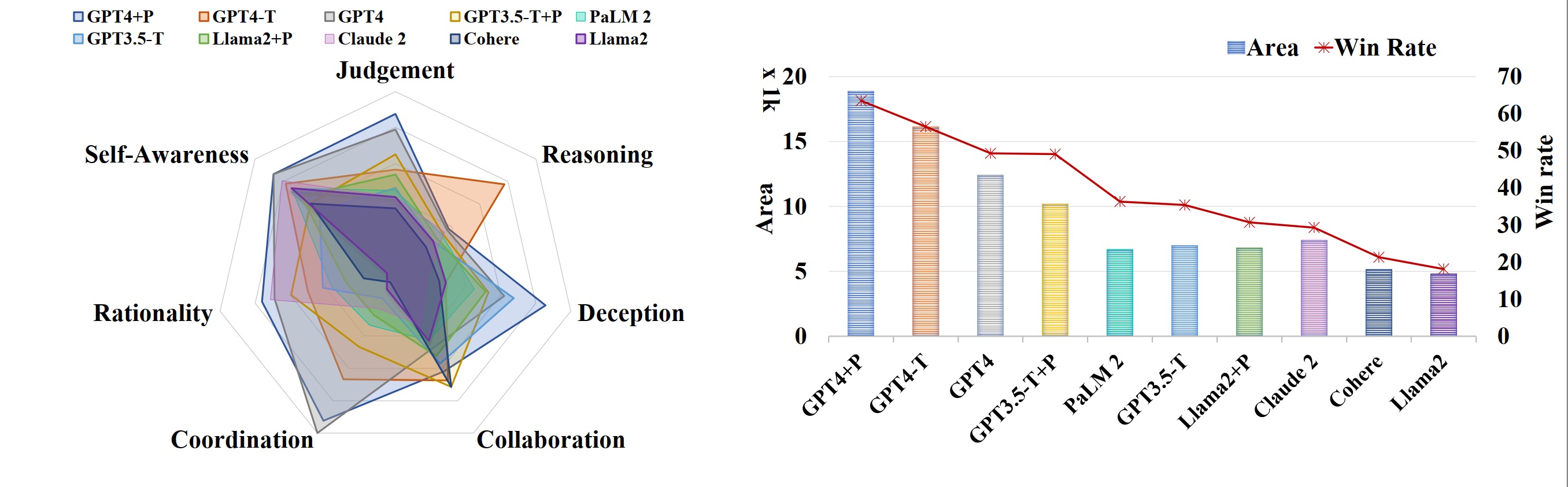
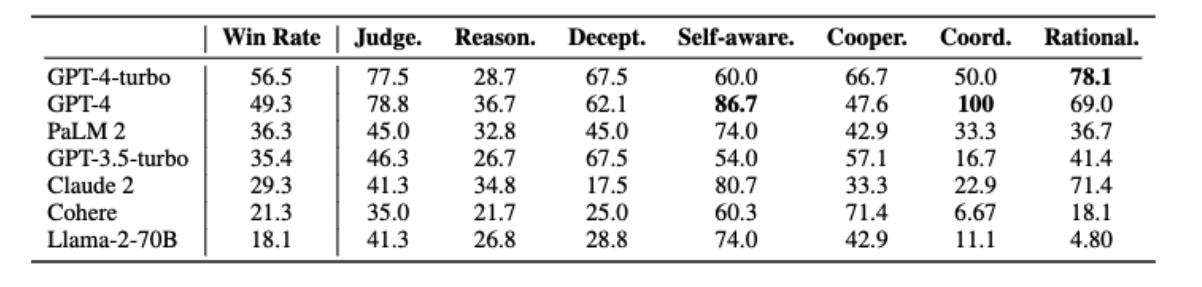
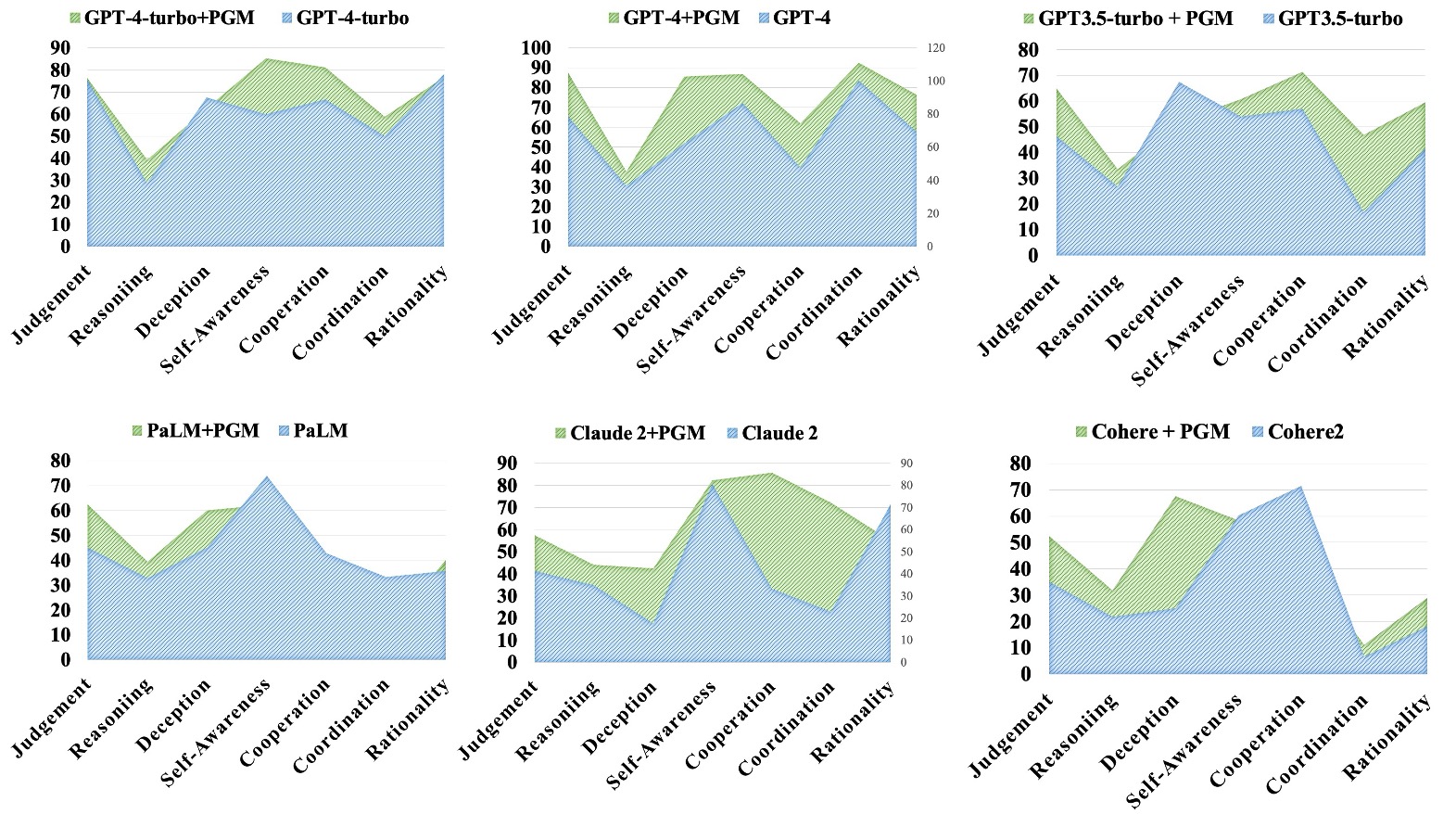
The radar diagram on the left illustrates the performance of LLMs across various metrics. In the figure, "-T" denotes "-turbo", and "+P" denotes that the model has been augmented with PGM. The bar chart on the right denotes the area occupied in the radar diagram and the red line plots the average winning rates in all games. It is clearly observed that the larger the area occupied in the radar diagram, the higher the winning rates are. This justifies that the proposed evaluation metrics are good to reflect the capability of the language models. For more details please refer to Sec.